
Knowledge work is thoughtful - it is reflected in the gathering, synthesis, articulation, and management of information to achieve successful outcomes. We must be equally thoughtful about providing capable tools for use by knowledge workers in order to support the flexible ways in which they explore information spaces and carry out tasks.
What problem are we solving?
Helping users make the best use of content can benefit from richer data about the ways users think about the information they find and use. Richer data allows us to embed proactive information retrieval into interactive applications to support workflow, case management, decision support, and other knowledge-intensive computing systems. It also provides significant input to cognitive computing applications, where the applications become active partners in the user's work. This arises as "...experts are now demanding machines that can help them navigate and organize the raw materials for their complex work environments." (Sue Feldman and Hadley Reynolds, Need a digital assistant? KM World, 3.31.2015)
What we are exploring is how we can take "silos" of information and of work, and use an extremely lightweight (yet powerful) mechanism to bridge the silos and establish a network of data around the use of information. This article describes an approach we developed to support enterprise search and content synthesis for case management and research in legal and scientific/academic domains. The users' goals are to efficiently create new information products - reports, decision documents, briefings, articles, books - that are informed by deep research into large content repositories (typically millions, or tens of millions, of documents from many repositories). To achieve this, they carry out evidence gathering, hypothesis building, and concept organization to establish reasoning and arguments. Through extensive user research, we identified ways that users thought about information-selecting decisions, captured notes and snippets, and then iterated on the found information over days, weeks, or months during the course of a case or project.
The approach centers on a lightweight annotation-based selection of potentially useful documents for iterative evaluation throughout the information gathering and work product authoring process. Our design goal was to streamline the way people evaluate, manage, and use enterprise content throughout the lifecycle of their work. This helps applications support users with immediate tasks, as well as longer-term knowledge retention and access to commonly used information. And the organization benefits by identifying patterns and key resources that help improve relevance and critical information use.
Capturing data from user selections
Every day, we all run searches and make selections of "interesting" and potentially useful documents and web pages. We’re used to seeing a small amount of snippet text in results and making quick decisions, selecting results that we find interesting and then gathering our selections into sets of items for further review. This well known process is illustrated below.
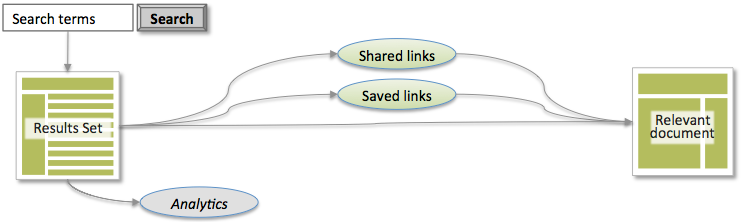
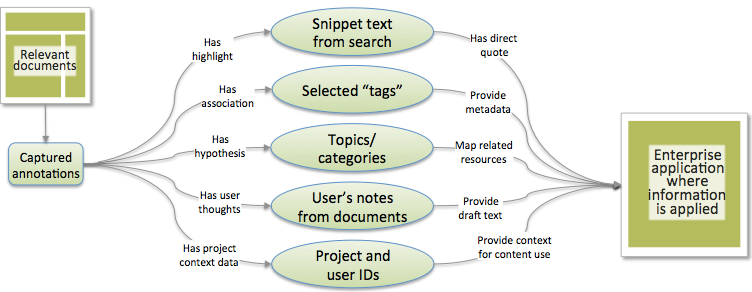
Selecting individual titles seems like the simplest part of the task. While keeping that action simple, we crafted an approach that also provides significantly more information to allow supporting applications to offer much more sophistication to users. The key is an underlying data model that captures the selection as an annotation on the item, allowing valuable additional data to be captured and used in various ways by our applications. Adding an annotation structure to the process is illustrated below.
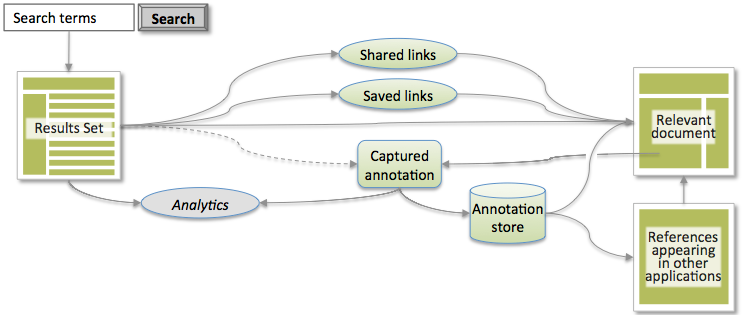
User selection data as an annotation
The model is applied in two scenarios: When a person selects an item from a results list, and also when a specific document is opened from a results list and then selected for later review in their task. Below is our model of the annotation data, illustrating the typical types of data captured in the two scenarios.
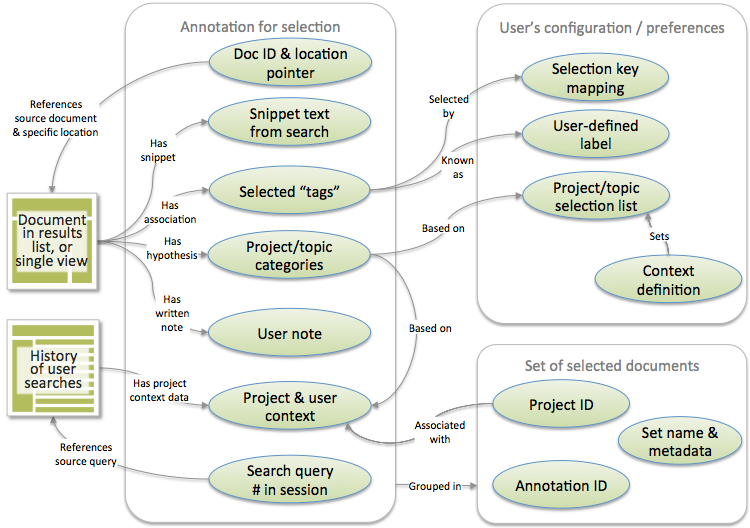
As illustrated above, the annotation-based approach captures:
- Project context associated with the selection;
- Search terms/phrases, operators, and filters that are used to target concepts within documents, and the alignment between what is sought and what is selected;
- Identification of the search phrase within a sequence of searches in the same session (maintaining a history of searches in a session provides insight into the evolution of thinking);
- Any selection categorization or grouping (e.g. flagging a selected document by using a number key as rapid categorization, or selecting a document by associating it with a project folder in a saved workspace) as well as user-defined categorization (user tagging);
- Interests or hypotheses captured in any note that the user makes as part of selection.
One of the data elements in the model is a location pointer within the selected document. This is achieved by making results snippets interactive elements, and/or displaying selectable thumbnails for images inside the retrieved document. The aim is to identify what is of particular interest to users, capturing selection data at a greater granularity than is currently captured in most implementations, then making that location pointer data machine-accessible when users need it later.
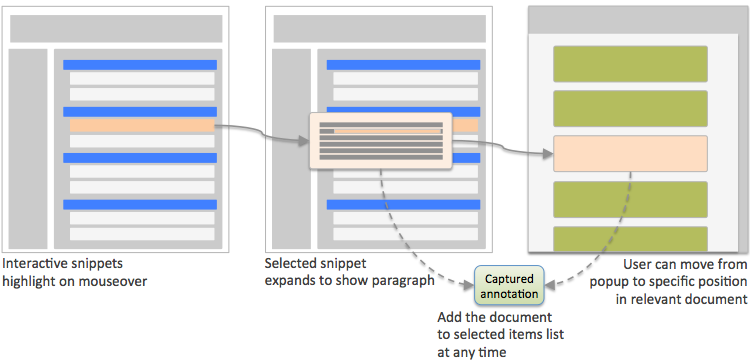
Applying high-quality materials to work products
A key driver of this annotation-based approach has been to streamline the ways that research and information gathering can be made available directly when people are creating work products and collaboratively working on activities. Capturing additional data ties the working context to found information. When a person is reading a previously selected reference document, the highlights and original search context help to re-focus quickly on areas of interest.
Capturing search selections in this way allows enterprise applications to support users as they start using the knowledge gained from inside these documents.
- The references can be organized and evaluated by the user over time (for an example of this, see Sewing the Seams of Sensemaking, Hearst & Degler, HCIR 2013), identifying key concepts within documents, and pruning documents that are no longer useful to the task.
- It is easier to incorporate research content drawn from the set of resources collated directly from search results selections, rather than having to copy/paste from a separate manually curated list.
- Regularly selected documents can be incorporated into a personal reference library for each user, helping them organize their "at hand" materials.
- Citations and individual quotes/snippets can be made available conveniently in content authoring applications, and organized in ways that relate to the sections inside those project documents.
Overall, this additional data means tighter integration with enterprise applications. Content (and fragments of content, as quotes/references) are easily applied into work products like reports, briefings, or authored legal decisions.
What do we learn from selections in search results?
We learn a great deal about what people are thinking when performing searches for information, their mental model for approaching a project's information needs, and their evaluation processes when presented with results and iterating searches. This can be used to help optimize the search process as they work, and also provide feedback to system managers for long-term tuning and improvement.
Based on what is learned, the search process could be refined in real time to increase personalization, suggest additional terms/approaches for follow-up searches, adjust ranking order, and present adaptive user interface components that improve or extend support of a user's task.
What do we learn from selection when reading a specific document?
It is important to know what documents deserve greater focus - opening for more detailed reading. The time spent in a document, and how people move through the document, help us understand the way that different types of content (and the embedded concepts) are consumed. Since there are typically common structures to organizational documents, this helps the content creators identify necessary changes to template structures and the information they produce (helpful for content governance). It also provides additional input to semantic analysis of documents, where a machine learning engine can be tuned based on context identified from user behaviors.
How do we capture annotation-based information related to search, when viewing a specific document? When a specific document is opened from the results page, this approach carries data from their search selection along to the document view. And once the document is selected (and thus annotated), it carries that data when it is grouped in a selected set of documents that are flagged for further more detailed review (even in a future session). The history of selection is not lost.
In cases where the user adds a document to a set of selected resources only after viewing it in detail, there is additional data to capture:
- What page or paragraph was visible on the screen at the point of selection;
- Whether that view has highlights from the search string that brought it to the user’s attention;
- Whether additional searching within a document has been performed;
- Additional indicators of whether other people had used these concepts (and cited the document) in previous work in the same context.
Feedback loop: Ongoing learning from selection patterns
When an application can recognize the source of a reference and its use, it can make a connection back from that end use to the context in which the source document was found and selected. So all the data captured during selection can now be mapped to the resulting context/outcome. This is important for knowledge management applications to identify content value.
Once we have that rich network of use established, we can apply its insights by integrating it with other enterprise information sources, such as departmental performance criteria, decision quality metrics, transactional data, long-term trend data, etc. In this way, it becomes a valuable input to governance processes, at both the organizational and content levels. The uses of this information for organizational and content governance are explored further in my article Intelligent understanding of content use (in KM World, vol 25 issue 3, 3.1.2016).
Supporting the individual user's experience, this approach helps to expand the capabilities of information collected into a highly contextualized personal reference library. Users are able to find concepts quickly that relate to their current working context, as well as ideas that cross conceptual boundaries, encouraging synthesis and development of new ideas.
In the longer-term, matching search behaviors with the actual use of concepts within retrieved documents provides deeper data for analytics and tuning of enterprise search systems. It also allows search to become more proactively integrated into enterprise applications, surfacing relevant content in more convenient and valuable ways over time. Proactive search algorithms and recommendation systems will benefit from the ongoing availability of contextually modeled content, the use of that content in work products, and rich mapping of content into personal reference libraries. These capabilities are very important as the scale of enterprise and public content continues to escalate dramatically – in terms of the number of files/datasets, the array of formats, the diversification of repositories, and the size of individual content items.
Conclusion
The annotation system acts as "glue" between what is retrieved through search and browse, and the work products that result from the use of relevant and timely information. This approach increases the usefulness of intelligent application support during information-gathering activities. It also provides a wealth of valuable data to help optimize content management, user relevance, and governance of content and the organization. Cognitive computing applications will benefit from this deeper visibility into the users' selection process, and can pass that benefit back to the user in the form of more efficient and effective outcomes.